
Назад
 Начало Начало |
 Учебные материалы Учебные материалы |
Другие разделы
Дата и время
19/07/2026 02:16:59
 Функциональное программирование
Функциональное программирование
Функции и программирование Списки. Функции для работы со списками Определение новых функций Функции высших порядков и /\-выражения Представление и выполнение функциональных программ Виды вычислений. Карринг. Конвейеры. Запоминание. Монады Интерпретация и компиляция функциональных программ Функции высших порядков. Обозначение типа Чистое /\-исчисление. Комбинаторная логика
Интерпретация и компиляция функциональных программ
Рассмотрим реализацию энергичного интерпретатора функциональных программ, представленных в виде S-выражений. Ограничим эту реализацию базовыми функциями для работы со списками и управляющими конструкциями. Интерпретатор можно легко перевести на любой язык программирования и расширить, добавляя новые функции по аналогии.
Контекст проще всего представить в виде двух списков: `n` – список имен и `v` – список значений. Например, пусть `n`=((X Y Z) (A X F)) и `v`=((1 (A B) –127) (C 3 ((lambda (X) (+ X 1)) . …))), тогда контекст имеет вид `{X\ ->\ 1,\ Y\ ->\ (A\ B),\ Z\ ->\ –127,\ A\ ->\ C,\ F\ ->\ [(lambda\ (X)\ (+\ X\ 1)),\ …]}`. Список `n` состоит из нескольких подсписков, которые являются наборами связей, добавляемых на разных этапах вычислений. В этом примере связь `X\ ->\ 3` временно вытеснена связью `X\ ->\ 1`. Функциональное замыкание будем представлять в виде S-выражения `(lambda\ .\ (n\ .\ v))`, где `lambda` – `lambda`-выражение, а `n` и `v` – состояние контекста в момент определения функции (значения свободных переменных также содержатся в этом контексте).
Для доступа к контексту используется функция `"ассоц"(x,n,v)`, которая по имени `x` из списка имен `n` выдает соответствующее значение из списка значений `v`. Если имени в списке `n` нет, то результат не определен.
`"ассоц"(x,n,v)=bb"если"\ "содержит"(x,"car"(n))\ bb"то"\ "найти"(x,"car"(n),"car"(v))``bb"иначе"\ "ассоц"(x,"cdr"(n),"cdr"(v))`;
`"найти"(x,s,t)=bb"если"\ "eq"(x,"car"(s))\ bb"то"\ "car"(t)\ bb"иначе"\ "найти"(x,"cdr"(s),"cdr"(t))`
Кроме того, потребуются дополнительные функции для получения списка переменных, определяемых в блоке локальных определений, для получения списка выражений этого блока и для вычисления списка выражений.
`"перем"(s)=bb"если"\ "null"(s)\ bb"то"\ '()\ bb"иначе"\ "cons"("caar"(s),"перем"("cdr"(s)))`;`"выр"(s)=bb"если"\ "null"(s)\ bb"то"\ ‘()\ bb"иначе"\ "cons"("cadar"(s),"выр"("cdr"(s)))`;
`"вычспис"(e,n,v)=bb"если"\ "null"(e)\ bb"то"\ '()`
`bb"иначе"\ "cons"("вычислить"("car"(e),n,v),\ "вычспис"("cdr"(e),n,v))`
Основной функцией программы является функция `"вычислить"(e,n,v)`, которая вычисляет S-выражение `e` в контексте `n` и `v`.
`"вычислить"(e,n,v)=``bb"если"\ "atom"(e)\ bb"то"\ "ассоц"(е,n,v)`
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"quote")\ bb"то"\ "cadr"(e)`
/* обработка базовых функций работы со списками */
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"car")\ bb"то"\ "car"("вычислить"("cadr"(e),n,v))`
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"cdr")\ bb"то"\ "cdr"("вычислить"("cadr"(e),n,v))`
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"atom")\ bb"то"\ "atom"("вычислить"("cadr"(e),n,v))`
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"cons")\ bb"то"`
`"cons"("вычислить"("cadr"(e),n,v),\ "вычислить"("caddr"(e),n,v))`
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"eq")\ bb"то"`
`"eq"("вычислить"("cadr"(e),n,v),\ "вычислить"("caddr"(e),n,v))`
/* обработка управляющих предложений */
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"if")\ bb"то"`
`"вычислить"(bb"если"\ "вычислить"("cadr"(e),n,v)\ bb"то"`
`"caddr"(e)\ bb"иначе"\ "cadddr"(e)\ ,n,v)`
`bb"иначе"\ bb"если"\ "eq"("car"(e),'lambda)\ bb"то"`
`"cons"(e,"cons"(n,v))`
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"let")\ bb"то"`
`{"вычислить"("caddr"(e),"cons"(y,n),"cons"(z,v))`
`bb"где"\ y="перем"("cadr"(e));`
`z="вычспис"("выр"("cadr"(e)),n,v)}`
`bb"иначе"\ bb"если"\ "eq"("car"(e),'"letrec")\ bb"то"`
`{{"вычислить"("caddr"(e),"cons"(y,n),"set"_"car"(w,z))`
`bb"где"\ z="вычспис"("выр"("cadr"(e)),"cons"(y,n),w)}`
`bb"где"\ y="перем"("cadr"(e));`
`w="cons"(‘(),v)}}`
`bb"иначе"` /* вызов функции */
`{"вычислить"("caddar"(с),"cons"("cadar"(c),"cadr"(c)),"cons"(z,"cddr"(c)))`
`bb"где"\ с="вычислить"("car"(e),n,v);`
`z=\ "вычспис"("cdr"(e),n,v)}`
При выполнении рекурсивного блока (letrec `((x_1\ e_1)\ …\ (x_k\ e_k))\ e)` для создания контекста используется псевдофункция `"set"_"car"(x,y)`, которая разрушает уже существующую структуру данных, что запрещено в функциональном программировании. Действие этой функции заключается в замене первого элемента списка `x` на `y`. В языке Scheme эта функция имеет имя set–car!. С ее помощью можно построить циклические структуры, что и требуется для интерпретации рекурсивного блока. В принципе можно определить вычисление блока letrec без использования разрушающей псевдофункции, но для этого потребуется ленивая семантика языка. При вычислении значений выражений `e_1,\ …,\ e_k` значения для `x_1,\ …,\ x_k` еще недоступны, поэтому выражения `e_1,\ …,\ e_k` не должны требовать немедленного доступа к `x_1,\ …,\ x_k`, то есть должны быть функциями.
Чем больше возможностей (базовых функций, управляющих конструкций, способов вычисления аргументов функции) мы будем включать в язык, тем более сложным будет интерпретатор и сложнее его переделка. Обычно программа на языке LISP или Scheme преобразуется в программу на языке гораздо более низкого уровня, похожем на машинный язык, который может выполняться с гораздо большей скоростью. Интерпретатор этого простого языка написать гораздо легче и его легче изменять. Компилятор может быть написан на базовом языке и преобразован вручную. Все последующие версии компилятора транслируются с использованием предыдущей версии.
SECD-машина для интерпретации LISP-программ получила свое название по начальным буквам ее регистров. Каждый из регистров содержит указатель на S-выражение.
Таблица 2
Назначение регистров SECD-машины
| Регистр | Назначение |
| Stack | Стек для размещения промежуточных результатов во время вычисления выражения |
| Environment | Служит для хранения значений, связываемых с переменными во время вычисления, соответствует списку значений `v` в интерпретаторе. |
| Control list | Указатель на выполняемую команду программы |
| Dump | Стек для хранения других регистров при вызове новой функции |
Для ускорения доступа к значениям переменных вместо последовательного поиска в контексте используются индексные пары `(i\ .\ j)`, где `i` – номер списка, а `j` – номер элемента в списке. Определение индекса значения происходит во время компиляции.
Программа (cons (+ x 1) (cdr y)) может быть преобразована компилятором в следующий код: ((LOAD 0 . 0) (QUOTE . 1) + (LOAD 0 . 1) CDR CONS). Выполнение команд SECD-машины легко описать с помощью таблицы 3.
Таблица 3
| Начальное состояние регистров | Конечное состояние регистров | ||||||
| S| | E| | C| | D| | S| | E| | C| | D |
| `s` | `e` | `(("LOAD"\ i\ .\ j)\ .\ c)` | `d` | `(v\ .\ s)` | `e` | `c` | `d` |
| `s` | `e` | `(("QUOTE"\ .\ v)\ .\ c)` | `d` | `(v\ .\ s)` | `e` | `c` | `d` |
| `(a\ b\ .\ s)` | `e` | `(+\ .\ c)` | `d` | `(a+b\ .\ s)` | `e` | `c` | `d` |
| `((a\ .\ b)\ .\ s)` | `e` | `("CDR"\ .\ c)` | `d` | `(b\ .\ s)` | `e` | `c` | `d` |
| `(a\ b\ .\ s)` | `e` | `("CONS"\ .\ c)` | `d` | `((a\ .\ b)\ .\ s)` | `e` | `c` | `d` |
Кроме S-выражений, функциональную программу можно представить также в виде графа (рис. 4), для обработки которого используется G-машина, и потокового графа (рис. 5), для обработки которого используется потоковая машина.
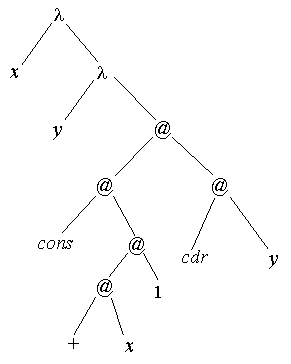 | 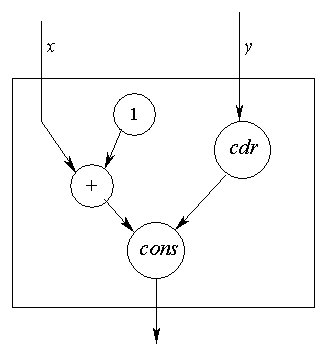 |
| Рис. 4 | Рис. 5 |
В функциональном языке программист не заботится явно о размещении новых объектов в памяти и удалении их после того, как объект перестанет быть необходимым. Поэтому очень важной является сборка мусора, которая запускается каждый раз при нехватке памяти для дальнейшей работы функциональной программы. Для SECD-машины сборка мусора состоит в том, что все ячейки памяти, к которым нет прямых или косвенных ссылок из регистров, переводятся в список свободных ячеек памяти. Основные классы сборщиков мусора описаны в главе 16 книги Филд А., Харрисон П. "Функциональное программирование".
